




Decision Trees
Decision Trees are a popular machine learning algorithm used for both classification and regression tasks. They are a non-parametric supervised learning method.
Basic Structure:
- Node: Represents a feature or attribute.
- Branch: Represents a decision rule.
- Leaf: Represents an outcome or decision.
How Decision Trees Work:
- Start with the dataset at the root.
- Split the datasets into subsets based on a decision rule (e.g., “Is age > 50?”). This rule is determined based on feature values.
- Repeat the splitting process recursively, generating new tree branches.
- Continue the process until a stopping criterion is met, like a maximum depth of the tree or a minimum number of samples per leaf.
Algorithm to Build a Decision Tree (like CART – Classification and Regression Trees):
- It uses a metric like Gini impurity or entropy for classification and mean squared error for regression to evaluate the quality of a split.
- It examines every possible split for each attribute and chooses the one that results in the lowest impurity (or error for regression) for the target variable.
Strengths:
- Simple to understand and visualize.
- Requires little data preprocessing (e.g., no need for scaling).
- Can handle both numerical and categorical data.
Limitations:
- Prone to overfitting, especially with deep trees.
- Can be unstable due to small variations in data.
- Often not as accurate as other algorithms when used alone.
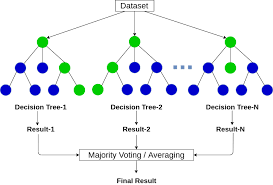
Random Forests
Random Forests is an ensemble learning method that creates a ‘forest’ of decision trees. Each tree is trained on a random subset of the data and gives its own prediction. The Random Forest algorithm aggregates these predictions to produce a final result.
How Random Forests Work:
- Bootstrapping: Sample randomly with replacement from the dataset, creating several different datasets.
- Building: For each of these datasets, a decision tree is built. When building the tree, at each node, a random subset of features is chosen to decide the best split (instead of considering all features). This introduces more diversity and decorrelates trees.
- Prediction:
- Classification: Each tree votes for a class, and the class receiving the most votes is the forest’s prediction.
- Regression: The average prediction of all the trees is taken.
Strengths:
- Reduces overfitting compared to individual decision trees.
- Handles missing values and maintains accuracy for missing data.
- Can be used for both classification and regression tasks.
Limitations:
- Less interpretable than a single decision tree.
- Longer training time because of building multiple trees.
- Predictions can be slower if the forest is very large.
In summary, while decision trees are a powerful algorithm, they are prone to overfitting and might not be the best in terms of prediction accuracy. Random Forests, on the other hand, combine the predictions of multiple trees to produce a more robust and accurate model, often making them a preferred choice for many machine learning tasks.



