


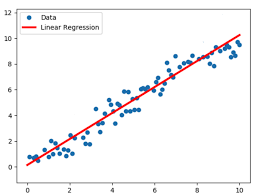
Linear Regression is one of the simplest and most widely used statistical techniques in machine learning for predicting a continuous outcome variable based on one or more predictor variables.
Basic Idea: The core idea behind linear regression is to fit a straight line (in simple linear regression) or a hyperplane (in multiple linear regression) to the data in such a way that the differences between the observed values and the values predicted by the line or hyperplane are minimized.
Mathematical Representation: For simple linear regression with one predictor variable: y=β0+β1x+ϵ Where:
- y is the dependent variable we are trying to predict.
- x is the independent variable, or the predictor.
- 0β0 is the y-intercept.
- 1β1 is the slope of the line.
- ϵ is the error term, representing the difference between the observed value and the predicted value.
For multiple linear regression with multiple predictor variables:
y=β0+β1x1+β2x2+…+βpxp+ϵ
Learning the Coefficients: The objective of linear regression is to learn the coefficients β) that result in the smallest sum of the squared differences (errors) between the observed outcomes and the outcomes predicted by the model. This method is called the “Least Squares Method”.
Assumptions: Linear regression makes several assumptions:
- Linearity: The relationship between the predictors and the outcome variable should be linear.
- Independence: Observations should be independent of each other.
- Homoscedasticity: The variance of the errors should be constant across all levels of the independent variables.
- Normality: The errors should be normally distributed (more crucial for smaller sample sizes).
- No multicollinearity (for multiple linear regression): Predictor variables should not be highly correlated with each other.
Applications: Linear regression can be applied to various domains such as economics (predicting GDP), healthcare (predicting disease progression), real estate (predicting house prices), and many others.
Limitations:
- It assumes a linear relationship between predictors and the outcome variable. If the relationship is non-linear, linear regression may not produce the best predictions.
- It can be sensitive to outliers.
- Predictions can fall outside of plausible value ranges (e.g., predicting negative prices).
Extensions: For scenarios where the assumptions of linear regression are not met, there are many extended techniques, such as polynomial regression, ridge regression, lasso regression, and others.
In practice, linear regression is often one of the first algorithms tried on a regression problem, given its simplicity and interpretability. If it doesn’t perform well, practitioners usually move to more complex algorithms or try to refine the features or the model.

